MEDIA
HELP
OTHER PRODUCTS

Artificial intelligence (AI) is a topic that gained a lot of popularity in the computer science field in the last years. Before using AI, the experts had to find the best rules to make the program run in a way that fulfilled the user requirements. Now, people discovered the power of this technology and learned how to configure it to generate the necessary rules. The repetitive steps are automated and a model is generated based on the real data. The beauty of this technology is that even people that are not experts in the domain can use the computer to model their data.
Natural language processing (NLP) is a subfield of artificial intelligence that aims to analyze and understand human language. The computer is capable of processing a large number of documents, extract relevant information, and organize the documents themselves.
The content migration process can be simplified by using artificial intelligence capabilities. Sometimes the target ECM application requires attributes that are not present in the source platform and manual processing of the documents is necessary to identify these attributes. To help the users solve this issue, we implemented a new Enrich Scanner into migration-center which uses Amazon Comprehend capabilities.
Amazon Comprehend is a natural language processing (NLP) service that uses machine learning to extract insights from a text. Computational power is correlated to success in AI. One benefit of using this Amazon Web Service (AWS) is that the classifier can be trained on their cloud system, so the users are not required to own a system with enough resources to train their model.
The service contains a lot of built-in classifiers like Entity Recognition and Language Detection, named standard classifiers. The user can work with the existent classifiers if they meet the requirements. Amazon Comprehend offers a lot of flexibility by allowing the users to create their custom classifier and custom entity classifiers. Those are trained one time and can be used every time the user wants to.
There are a lot of content migration use cases that can be improved by natural language processing. The most relevant and common use cases are:
For example, in a possible use case the target platform requires some attributes to be set, but those attributes are not provided in the source system.
After the objects are scanned from the source system, the user can configure an Amazon Comprehend Enrich Scanner to obtain the missing attributes from the documents itself. The scanner supports endpoint for entity recognition, language detection, and custom classifiers. By using one or multiple classifiers, the attributes can be extracted automatically from the content files. If the use case is not completely covered by the standard classifiers, the users can even utilize documents from the target system to train their custom classifier.
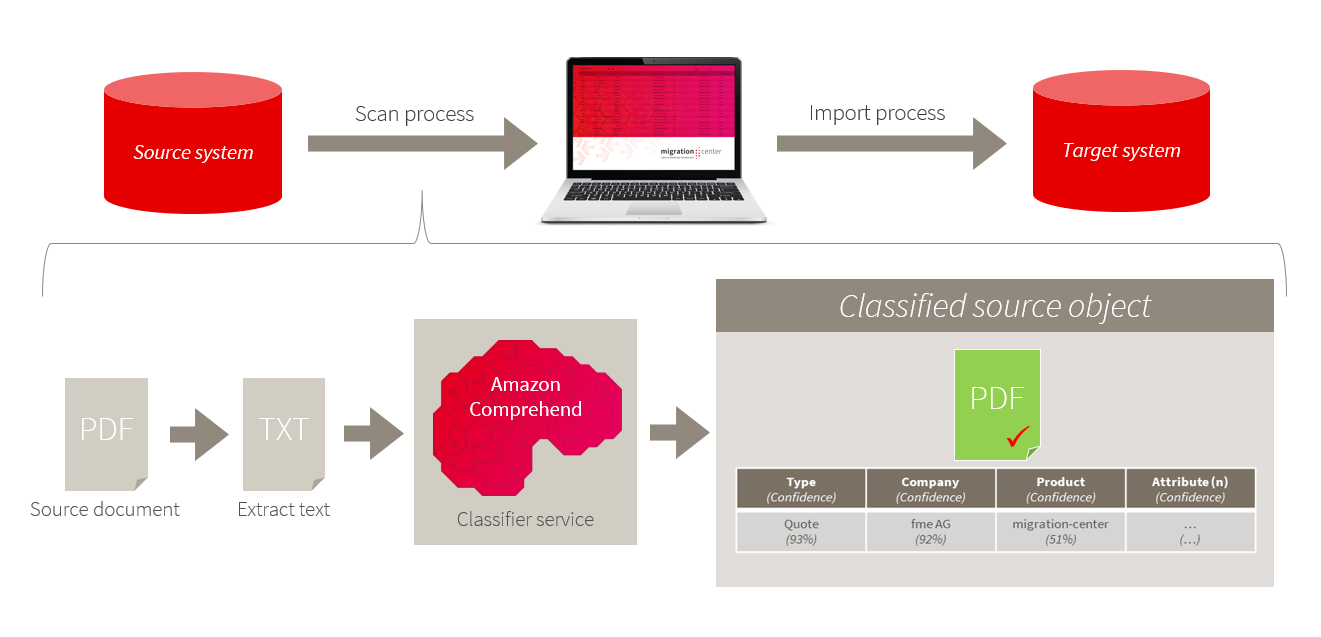
The use of Amazon Comprehend Enrich Scanner
migration-center’s Amazon Comprehend Enrich Scanner analyzes Office documents with OCR. The extracted text files are uploaded to S3 storage and the configured classifiers are triggered. When the jobs are done, the scanner enhances the source objects with the generated attributes. For example, the classifier is 95 % sure that the words “fme AG” represent a company.
For every attribute, the scanner assigns a percentage value named score, which represents the confidence of the prediction. Using the transformation rules, the user can filter the attributes based on score value. If the confidence of the attribute is 45 % for instance, then the attribute should not be set in the target system.
MEDIA
HELP
OTHER PRODUCTS

 Migrating a leading healthcare company to Veeva Vault RIM
Migrating a leading healthcare company to Veeva Vault RIM