MEDIA
HELP
OTHER PRODUCTS

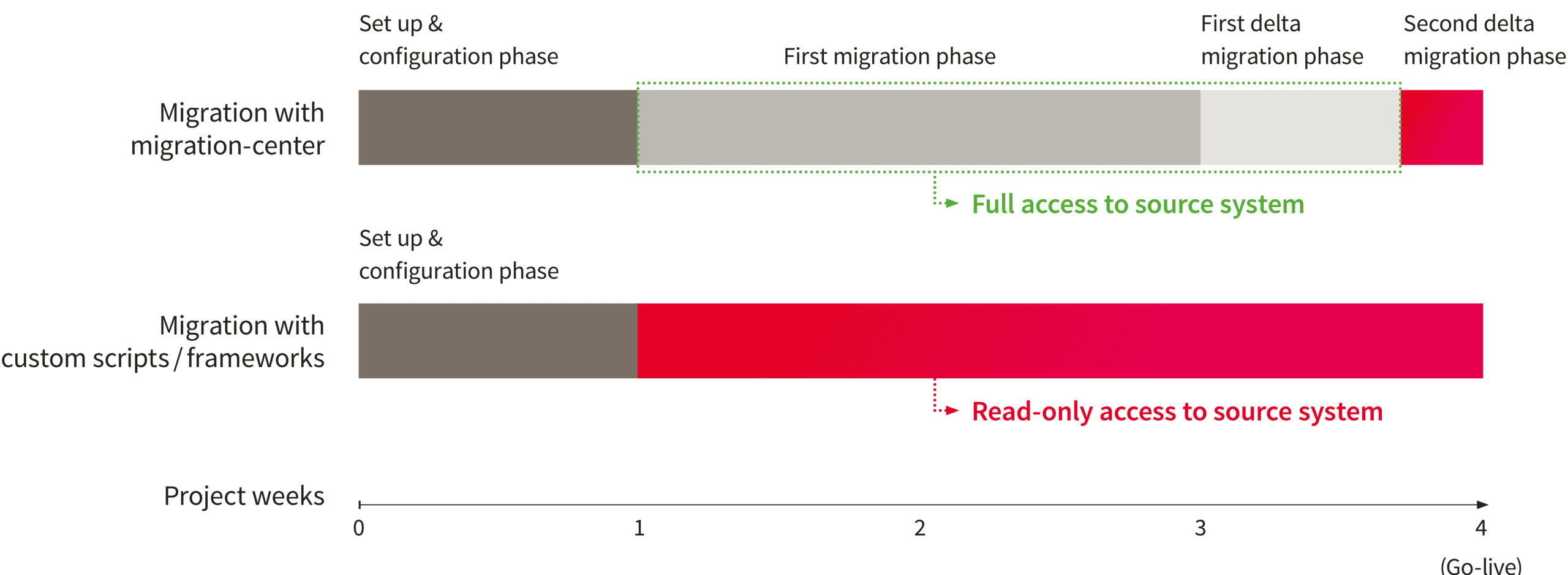
The implementation of a very large data migration project raises many challenges. One of them being how to handle user downtime when making the switch between the old and the new system. The solution that migration-center offers is its so-called “delta migration” capability. This allows the migration to be split into two distinct phases: Initial migration and delta migration.
Using migration-center you can scan, transform and import very large amounts of documents from one system to another (by the way, here is a list of source and target systems supported by migration-center). Depending on the actual number of documents and, more importantly, the complexity of the required metadata transformations, this can take from days to weeks.

migration-center comes with a best practices-based predefined migration approach to migrate up to large data volumes from one system to another.
Typically, the start of a migration project begins with an analysis, and before the documents reach the target system in production, migrations are first performed in development and test environments. All this can be done without restricting end-user access to the source system.
After the initial migration, most of the data is in the new system. However, as users still had access to the existing system, the data in the new system does not match the data 100%. New documents or versions are created, and what is more crucial, changes are made to existing documents and versions. These changes can relate to metadata or even to the actual content of the documents.
This is where the delta migration comes in handy. If you re-run the same source connectors (or create copies of the existing ones), migration-center ignores all documents that have already been scanned and have not been modified since. Thus, only new or changed documents are picked up. In case of altered documents, the scanned objects in migration-center are marked by having the is_update internal attribute set to true.
If you have such update objects, it is very important that the original migset with the objects remains intact and that the objects inside still are in the imported state. If you deselect the objects in the migset or reset them, you lose the value in the id_in_target_system attribute, which is the only way the target connector can locate the already migrated document in the target system in order to update it.
Therefore, the best way to handle the update objects is to create a copy of the original migset and assign the delta scan run to it. After that, you can transform and import the objects as usual.
Thanks to migration-center’s delta migration capability, users continue to work as usual on documents on their source systems, even while in the background migration activities are taking place.
Even the delta migration does not have to be performed all at once. After the initial migration, you can expect to find a larger number of new documents and updates. However, since a delta run takes much less time than the initial migration, you can execute successive delta runs, finding fewer changed items each time. Finally, the system can be taken offline, for example over a weekend, and the last delta migration run can be performed right before making the switch to the new system. Thanks to this approach, user downtime is kept to a minimum.
Another common use for the migration of updated objects results in combination with the scheduler feature. The entire delta migration process described above can be automated into a continuous process by creating a scheduler.
A scheduler is a combination of source connector – migset – target connector, configured to run automatically at a specified interval.
This allows migration-center to be used as a tool for the synchronization of different systems.
When undertaking a migration project of a reasonable scope, managing user downtime is vital, as you cannot expect day-to-day operations to be interrupted for days or weeks until the migration is complete. Precisely in this context, migration-center’s delta migration feature allows you to complete a project with very little or no system downtime for users at all.
MEDIA
HELP
OTHER PRODUCTS

 Unlocking success together: Why ECM service providers should add migration-center...
Unlocking success together: Why ECM service providers should add migration-center...